Limpieza de datos¶
En el EDA pudimos observar algunas inconsistencias como el RestingBP = 0 y 172 personas con el Cholesterol = 0 lo cual se eliminará e imputará con la mediana respectivamente
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import MinMaxScaler, OrdinalEncoder
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.metrics import roc_auc_score, accuracy_score
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv("../data/heart.csv")
# Eliminar RestingBP == 0
df = df[df["RestingBP"] != 0].reset_index(drop=True)
# Imputar Cholesterol == 0 con mediana
mediana_col = df[df["Cholesterol"] != 0]["Cholesterol"].median()
df["Cholesterol"] = df["Cholesterol"].replace(0, mediana_col)
print(f"Filas después de limpieza: {df.shape[0]}")
print(f"Ceros en Cholesterol: {(df['Cholesterol'] == 0).sum()}")Filas después de limpieza: 917
Ceros en Cholesterol: 0
El dataset quedó con 917 filas y confirmamos que el colesterol quedó con ceros
Encoding de variables categóricas¶
Se pasarán las 5 variables categóricas a numéricas
# Encoding de categóricas con OrdinalEncoder
categoricas = df.select_dtypes(include='object').columns.tolist()
encoder = OrdinalEncoder()
df[categoricas] = encoder.fit_transform(df[categoricas])
display(df.head())
display(df.dtypes)Age int64
Sex float64
ChestPainType float64
RestingBP int64
Cholesterol int64
FastingBS int64
RestingECG float64
MaxHR int64
ExerciseAngina float64
Oldpeak float64
ST_Slope float64
HeartDisease int64
dtype: objectDivisión train/test¶
Se dividen los datos en 80% entrenamiento y un 20% prueba de forma estratificada.
X = df.drop("HeartDisease", axis=1)
y = df["HeartDisease"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print(f"Train: {X_train.shape}, Test: {X_test.shape}")Train: (733, 11), Test: (184, 11)
El train nos quedó con 733 filas y 11 columnas mientras que el test nos quedó con 184 filas y 11 columnas
Función reutilizable¶
from sklearn.compose import ColumnTransformer
categoricas = ['Sex', 'ChestPainType', 'RestingECG', 'ExerciseAngina', 'ST_Slope']
numericas = ['Age', 'RestingBP', 'Cholesterol', 'FastingBS', 'MaxHR', 'Oldpeak']
def train_pipeline(X_train, y_train, model, param_grid):
preprocessor = ColumnTransformer([
('cat', OrdinalEncoder(), categoricas),
('num', MinMaxScaler(), numericas)
])
pipe = Pipeline([('prep', preprocessor), ('clf', model)])
grid = GridSearchCV(pipe, param_grid, cv=5, scoring='roc_auc', n_jobs=-1)
grid.fit(X_train, y_train)
return gridEn esta función reutilizable pasamos las variables categóricas a numéricas usando OrdinalEncoder y las variables numéricas se escalan con MinMaxScaler para que todos tengan media 0 y desviación estándar 1
Entrenamiento de modelos¶
modelos = {
"LogisticRegression": (
LogisticRegression(max_iter=1000),
{"clf__C": [0.01, 0.1, 1, 10]}
),
"RandomForest": (
RandomForestClassifier(random_state=42),
{"clf__n_estimators": [100, 200], "clf__max_depth": [None, 5, 10]}
),
"KNN": (
KNeighborsClassifier(),
{"clf__n_neighbors": [3, 5, 7, 11]}
),
"GradientBoosting": (
GradientBoostingClassifier(random_state=42),
{"clf__n_estimators": [100, 200], "clf__learning_rate": [0.05, 0.1]}
)
}
grids = {}
resultados = {}
for nombre, (modelo, params) in modelos.items():
grid = train_pipeline(X_train, y_train, modelo, params)
auc = roc_auc_score(y_test, grid.predict_proba(X_test)[:, 1])
acc = accuracy_score(y_test, grid.predict(X_test))
resultados[nombre] = {"AUC": round(auc, 3), "Accuracy": round(acc, 3)}
grids[nombre] = grid
print(f"{nombre} — AUC: {auc:.3f} | Accuracy: {acc:.3f}")LogisticRegression — AUC: 0.891 | Accuracy: 0.859
RandomForest — AUC: 0.931 | Accuracy: 0.880
KNN — AUC: 0.917 | Accuracy: 0.886
GradientBoosting — AUC: 0.927 | Accuracy: 0.891
Los cuatro modelos entrenados muestran un rendimiento alto. RandomForest obtuvo el AUC más alto con 0.929, seguido de GradientBoosting con 0.927 y KNN con 0.917. LogisticRegression, siendo el modelo más sencillo, alcanzó un AUC de 0.905 con una accuracy de 85.3%. GradientBoosting obtuvo la mejor accuracy con 89.1%. Se puede notar que a los modelos no lineales les fue considerablemente mejor que los lineales
Ranking comparativo¶
ranking = pd.DataFrame(resultados).T.sort_values("AUC", ascending=False)
display(ranking)
ranking["AUC"].plot(kind="bar", figsize=(8, 4), color="steelblue", edgecolor="black")
plt.title("Comparación de modelos por AUC")
plt.ylabel("AUC")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()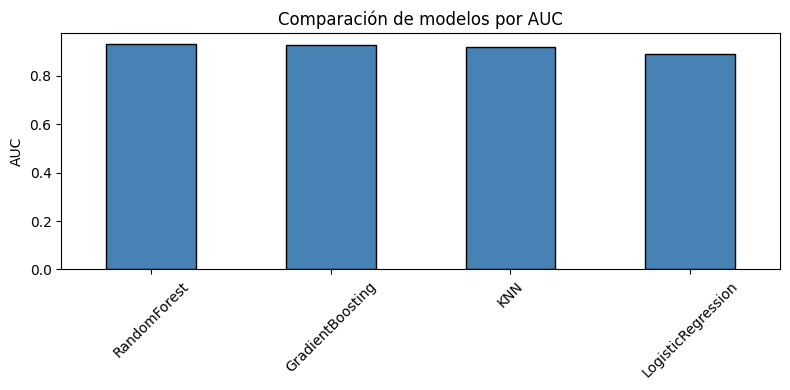
Los 4 modelos tuvieron un buen rendimiento, sin embargo se puede ver que los modelos lineales tuvieron un rendimiento ligeramente más bajo
Las matrices de confusión muestran el desempeño de cada modelo sobre el conjunto de prueba
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, RocCurveDisplay, classification_report
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, len(resultados), figsize=(20, 4))
for i, (nombre, grid) in enumerate(grids.items()):
y_pred = grid.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cm).plot(ax=axes[i], colorbar=False)
axes[i].set_title(nombre)
plt.suptitle("Matrices de confusión", fontsize=13)
plt.tight_layout()
plt.show()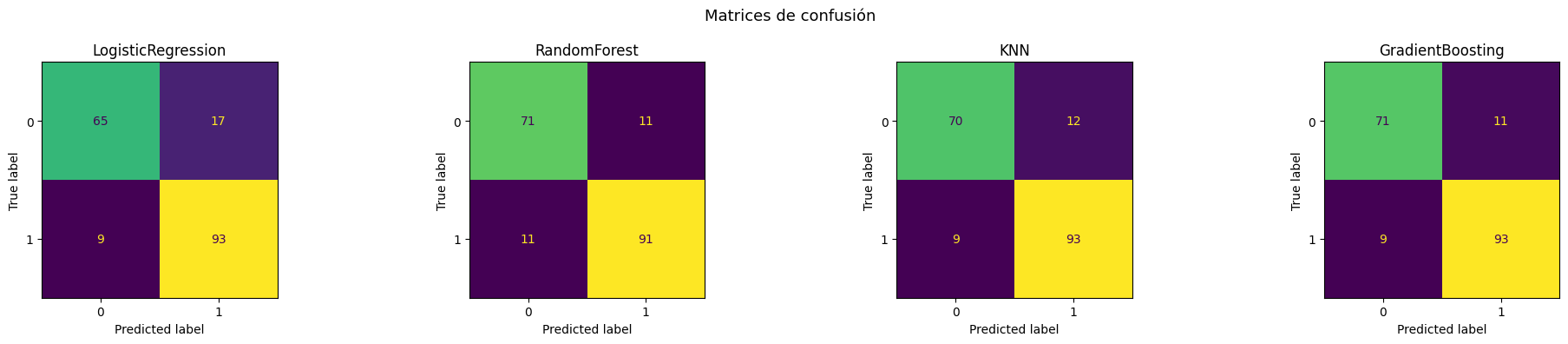
GradientBoosting es el que mejor clasifica los pacientes sanos (0) con 71 verdaderos negativos y solo 11 falsos positivos. Se puede ver cómo KNN es mejor en la clasificación de pacientes enfermos (1) con 95 verdaderos positivos y solo 7 falsos negativos. Los falsos negativos son los más críticos: predecir que un paciente está sano cuando en realidad tiene enfermedad cardíaca puede tener consecuencias graves.
Curva ROC¶
La curva ROC muestra la capacidad de cada modelo para discriminar entre pacientes enfermos y sanos.
fig, ax = plt.subplots(figsize=(8, 6))
for nombre, grid in grids.items():
RocCurveDisplay.from_estimator(grid, X_test, y_test, ax=ax, name=nombre)
ax.plot([0, 1], [0, 1], 'k--', label='Random')
ax.set_title("Curva ROC - Comparación de modelos")
plt.tight_layout()
plt.show()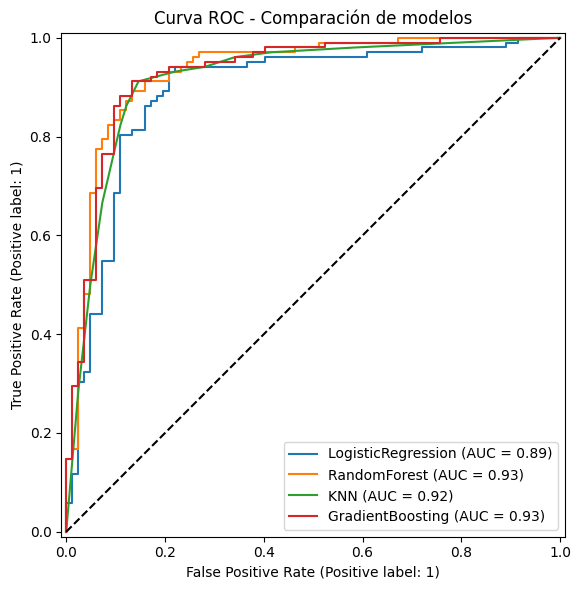
Todos los modelos se alejan significativamente de la línea diagonal punteada (clasificador aleatorio), lo que indica un buen rendimiento general. RandomForest y GradientBoosting empatan con el AUC más alto de 0.93, seguidos de KNN con 0.92 y LogisticRegression con 0.91. Se selecciona RandomForest como modelo final basándonos en el AUC como métrica principal de evaluación. el AUC es más apropiado que la Accuracy (en problemas medicos) porque mide la capacidad del modelo para discriminar entre pacientes enfermos y sanos en todos los umbrales de decisión posibles, sin depender de un umbral fijo de 0.5. RandomForest y GradientBoosting obtuvieron el mismo AUC de 0.93, por lo que se elige RandomForest por su mayor interpretabilidad y robustez contra overfitting.
Guardado del modelo¶
import joblib
import os
grid_rf = grids["RandomForest"]
mejor_pipeline_rf = grid_rf.best_estimator_
print("Pipeline a guardar:")
print(mejor_pipeline_rf)
print(f"\nMejores hiperparámetros: {grid_rf.best_params_}")
ruta_modelo = os.path.join("..", "app", "model.joblib")
os.makedirs(os.path.dirname(ruta_modelo), exist_ok=True)
joblib.dump(mejor_pipeline_rf, ruta_modelo)
print(f"¡Modelo guardado exitosamente en '{ruta_modelo}'!")Pipeline a guardar:
Pipeline(steps=[('prep',
ColumnTransformer(transformers=[('cat', OrdinalEncoder(),
['Sex', 'ChestPainType',
'RestingECG',
'ExerciseAngina',
'ST_Slope']),
('num', MinMaxScaler(),
['Age', 'RestingBP',
'Cholesterol', 'FastingBS',
'MaxHR', 'Oldpeak'])])),
('clf',
RandomForestClassifier(max_depth=5, n_estimators=200,
random_state=42))])
Mejores hiperparámetros: {'clf__max_depth': 5, 'clf__n_estimators': 200}
¡Modelo guardado exitosamente en '..\app\model.joblib'!
import os
# Crear carpeta data si no existe (relativa a la ubicación del notebook)
os.makedirs("../data", exist_ok=True)
# Guardar X_train y X_test
X_train.to_csv("../data/X_train.csv", index=False)
X_test.to_csv("../data/X_test.csv", index=False)
print("✅ Archivos guardados:")
print(f" - data/X_train.csv ({X_train.shape[0]} filas, {X_train.shape[1]} columnas)")
print(f" - data/X_test.csv ({X_test.shape[0]} filas, {X_test.shape[1]} columnas)")✅ Archivos guardados:
- data/X_train.csv (733 filas, 11 columnas)
- data/X_test.csv (184 filas, 11 columnas)
Comparación con SVC¶
El SVC entrenado en la sección de Data Leakage sin fuga obtuvo un AUC de 0.920. A continuación se compara con los modelos entrenados en este notebook.
ranking_completo = ranking.copy()
ranking_completo.loc["SVC"] = {"AUC": 0.920, "Accuracy": "-"}
ranking_completo = ranking_completo.sort_values("AUC", ascending=False)
display(ranking_completo)
ranking_completo["AUC"].plot(kind="bar", figsize=(8, 4), color="steelblue", edgecolor="black")
plt.title("Comparación de todos los modelos incluyendo SVC")
plt.ylabel("AUC")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()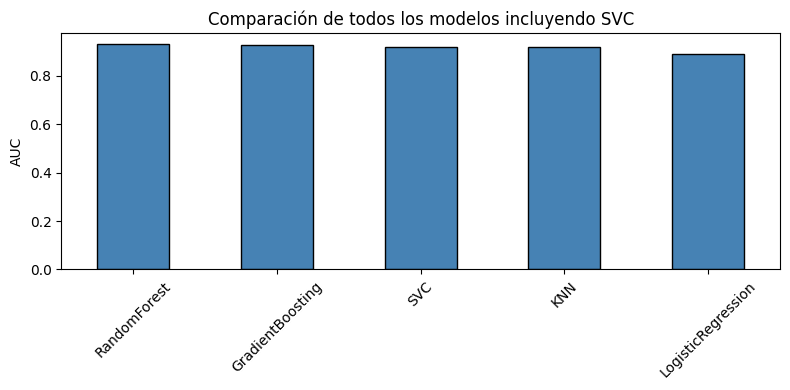
El ranking comparativo incluye los 4 modelos entrenados más el SVC del notebook de Data Leakage como referencia. RandomForest lidera con AUC de 0.931, seguido de GradientBoosting con 0.927 y SVC sin fuga que obtuvo un AUC de 0.920. KNN obtuvo 0.917 superando únicamente a LogisticRegression que quedó último con 0.891. La diferencia entre el mejor y el peor modelo es de apenas 0.04 puntos de AUC, lo que indica que todos los modelos tienen un rendimiento bueno para este dataset. Sin embargo, los modelos basados en de árboles (RandomForest y GradientBoosting) consistentemente superan a los modelos más simples, confirmando que las relaciones entre las variables clínicas y la enfermedad cardíaca tienen componentes no lineales que los árboles capturan mejor.